
Zuletzt geändert am 10. July 2026
Ich habe keinen dienstlichen Blog, weshalb ich diesen Beitrag über KI einfach hier in den Klimablog poste. KI hat insofern etwas mit Klima zu tun, als dass die KI-Firmen einen extremen Ressourcenverbrauch haben (Geräte, Energie, Wasser; siehe Bergt 2026). Die Frage, die man sich stellen muss, ist: Ist es das wert, dass man eine Suchanfrage in natürlicher Sprache stellen kann? Sind die Antworten brauchbar? Oder wäre es doch besser, einfach wie bisher Suchanfragen zu stellen und die Ergebnisse selbst einzuordnen? Wenn man klassisch sucht, kann man feststellen, dass die Seite XY einem nur Magnesium-Präparate verkaufen will, während auf der Seite AB eine Medizin-Professorin erklärt, dass ein selbst hergestelltes isotonisches Getränk (Fruchtsaft mit Salz) ausreicht, um Krämpfe nach Überanstrengung beim Sport zu verhindern (SWR zu Magnesium und Muskelkrämpfen).

Hier geht es aber nicht um solche Suchanfragen, sondern um komplexere Aufgaben. Aufgaben, die früher Wissenschaftler*innen oder deren Sekretär*innen erledigt haben. Konkret stelle ich eine Übersetzung eines Fachbuches und die Neubewertung eines Zitationsindexes vor.
Hintergrund
Ich bin promovierter Informatiker und habe zwischen 1997 und 2001 am Deutschen Forschungszenrtum für Künstliche Intelligenz (DFKI) in Saarbrücken gearbeitet. Ich war an der Entwicklung des Übersetzungssystems VerbMobil beteiligt und dort für die deutsche Grammatik zuständig (1997–2000). Ab 2000 habe ich für das Startup-Unternehmen Interprice weiter an der deutschen Grammatik gearbeitet und Arbeiten an anderen Sprachen koordiniert.
Ich habe mehrere Bücher geschrieben und in LaTeX gesetzt (1999, 2002, 2007, 2010, 2016, 2018, 2023, 2026). 2014 haben Martin Haspelmath und ich den Open Access-Verlag Language Science Press gegründet. Die Quelltexte aller Bücher sind auf github verfügbar und können also auch von KI-Firmen zum Training ihrer Modelle verwendet werden. Die rechtliche Situation ist unklar: Die Lizenz ist CC-BY. KI-Tools geben normalerweise nicht die Urheber*innen ihres Wissens an.
Übersetzung Fachbuch mit speziellen Layout-Elementen
Das Buch Germanic syntax habe ich auf Englisch geschrieben, um auch ein internationales Publikum zu erreichen. Ich nutze es seit einigen Jahren in der Lehre im BA Germanistische Linguistik. Ich denke, dass Studierende auch in der Lage sein müssen, englische Fachtexte zu lesen, aber bei Lehrevaluationen wird immer wieder die Sprache des Lehrbuchs angesprochen. Der Inhalt des Lehrbuchs ist komplex und wenn dann noch sprachliche Probleme dazukommen, kann sich Überforderung einstellen. Ich habe vor einiger Zeit mit einem Bekannten Claude AI für ein komplexes Projekt benutzt und dachte mir nun, dass es doch möglich sein müsste, das ganze Buch automatisch ins Deutsche übersetzen zu lassen. Ich habe ihn also gefragt, was er mir raten würde, welche Tools ich verwenden solle. Er hat mich nach der Größe des Buchprojekts gefragt und meinte dann, das sei für Claude AI wahrscheinlich zu groß. Dann meinte er, ich solle doch mal ein Kapitel schicken. Ich habe ihm das Kapitel zum Passiv geschickt. Er hat es an Claude AI weitergereicht und das war sein Prompt:
Kannst du das übersetzen, ohne es kaputt zu machen?Anforderungen
Das klingt, wie eine natürliche Anfrage an einen Menschen. Ganz viel ist implizit. Was ist in der Datei? Was darf nicht kaputt gehen? Claudia hat sich die Datei angesehen und hat festgestellt, dass es sich um eine LaTeX-Datei handelt, worum es in dem Text geht, und was nicht kaputt gehen darf:
🤖 Claude 2026-06-23T20:43:18.628Z
Ich habe die Datei gelesen. Das ist ein linguistischer Fachtext (offenbar ein Buchkapitel über das Passiv in den germanischen Sprachen, mit
\todostefan-Kommentaren — vermutlich aus Stefan Müllers Umfeld). Der Fließtext ist auf Englisch, und die Datei enthält jede Menge empfindliche LaTeX-Struktur:
- Interlinearglossen (
\gll… Quellzeile + Glossierungszeile)- Sprachmarker (
\german,\danish,\icelandic)- Index-/Sprachbefehle (
\is{},\ili{},\iw{}), Querverweise (\label/\ref/\mex), Zitate (\citet), Fußnoten- Objektsprachliche Beispielsätze (die deutschen/dänischen/isländischen Datensätze selbst)
„Ohne es kaputt zu machen“ heißt für so einen Text vor allem: die LaTeX-Struktur und vor allem die Sprachdaten in den Beispielen dürfen sich nicht ändern — sonst ist der Inhalt zerstört, auch wenn es noch kompiliert. Bevor ich an ~3300 Zeilen arbeite, brauche ich zwei Entscheidungen von dir, weil sie den Umfang grundlegend ändern und ein falsches Raten viel Arbeit zerstören würde.
Als Beispiel für die Komplexität der Aufgabe seien hier Beispiele aus dem Jiddischen angegeben:

Diese werden durch den folgenden Quelltext erzeugt:

Das Buch enthält komplexe Bäume, die Glossierungen enthalten. Die folgende Abbildung ist ein Beispiel:
Dieser Baum wird durch den folgenden Code erzeugt.

Claudia muss also den normalen Text übersetzen, die Beispiele in anderen Sprachen unangetastet lassen und die englischen Glossen ins Deutsche übertragen. Bei deutschen Beispielen werden keine Glossierungen gebraucht und englische Beispiele müssen als Beispiele und nicht zu übersetzender Text erkannt werden. Bäume enthalten auch Glossierungen, die aus dem Englischen ins Deutsche übertragen werden müssen, wenn die Beispiele nicht schon im Deutschen sind.
Interaktion
Claudia hat dann gefragt, in welche Sprache übersetzt werden soll und ob nur der Haupttext oder auch die Glossierungen übertragen werden sollen. Damit das Buch nutzbar wird, muss natürlich alles übersetzt werden. Es folgen Auszüge aus dem Interaktionsprotokoll. Das komplette Protokoll befindet sich im github-Repository.
🤖 Claude 2026-06-23T21:00:42.215Z
Verstanden: Englisch → Deutsch, Volllokalisierung (Fließtext + freie Übersetzungen
\glt+ Wort-für-Wort-Glossen), während die objektsprachlichen Datenzeilen (die dt./dän./isl. Beispielsätze selbst) sowie alle LaTeX-Befehle, Labels, Makros (\NOM,\DAT,\AUX…) und Zitate unangetastet bleiben.Nützlich: die auskommentierte deutsche Passage (Zeilen 736–762) zeigt bereits deinen/den intendierten Glossierungsstil (z. B.
sie.\PL.\DAT{} wurde geholfen). Daran orientiere ich mich.Ich lese zuerst den Rest der Datei vollständig, um Terminologie konsistent zu halten und keine Struktur zu übersehen.
[…]
Ich habe die gesamte Datei gelesen (3318 Zeilen). Das ist klar ein Kapitel aus Stefan Müllers HPSG-Lehrbuch. Bevor ich anfange, muss ich eine zentrale Sache klären, die über „kaputt oder nicht” entscheidet: die Index-/Sprachmakros wie
\ili{Danish},\is{subject|(},\iw{}. Ob ich deren Argumente mitübersetzen darf (z. B.\ili{Danish}→\ili{Dänisch},\is{subject}→\is{Subjekt}), hängt davon ab, wie diese Makros definiert sind — ob sie ihr Argument nur ausgeben oder es als Index-/Sprachdatenbank-Schlüssel verwenden. Ändere ich einen Schlüssel falsch, bricht der Index. Ich suche deshalb die Stildefinitionen.
Das bedeutet: Claude AI hat die Datei eingelesen, hat die Dokumentstruktur verstanden, weiß, was glossierte (Wort für Wort übersetzte) Beispiele sind, weiß, dass die Kommandos \is{subject} für den Index sind1 und weiß auch, dass das ein Kapitel aus meinem Buch ist. Claudia hat festgestellt, dass es die Definition des \is{}-Kommandos nicht kennt, weil die Dateien nicht heruntergeladen wurden und beginnt dann aber dennoch die Übersetzung. Sie verspricht auf passende Bereichsdefinitionen für den Index zu achten, d.h. zu jeder öffnenden Klammer gehört auch eine schließende und die Index-Übersetzungen müssen zueinander passen. Claudia legt eine Backup-Datei an und beginnt.
In der Nacht um 4 ist sie fertig und überprüft das Ergebnis. Auskommentierte Textpassagen lässt sie unverändert. Die Überprüfung ist 4:30 abgeschlossen. Mein Bekannter schickt mir am nächsten Morgen das Ergebnis. Das Ergebnis läuft ohne Probleme durch die LaTeX-Übersetzung. Falsch ist nur, dass deutsche Beispiele deutsch glossiert sind. (Sie hatte allerdings gefragt.)

Das ist natürlich in einer deutschen Version des Textes unnötig. (German) wird von einem Makro erzeugt, dass ich ändern muss. Das ist in einer Minute erledigt.
Caludia schreibt:
Unangetastet geblieben (bewusst)
Die objektsprachlichen Beispielsätze (dt./dän./isl. und die englischen Datenbeispiele wie „The child was given a novel.”),forest/tikz-Abbildungen, AVMs, alle%-Kommentare, Zitate, URLs, Labels und die Feature-Makros (\NOM,\AUX,\spr…).
Claudia weist selbst darauf hin, dass Glossen in Bäumen nicht bearbeitet wurden und schlägt vor, das in einem zweiten Durchgang zu machen.
Danach habe ich ein github-Repository erzeugt, das komplette Buch hochgeladen und Claudia um Folgendes gebeten:
Einzige Fehler, den ich jetzt sehen konnte, ist, dass die deutschen Beispiele geglosst und übersetzt werden. Das kann ganz weg. statt \gll Der Installateur kommt.\\ und dann glossen und \glt muss nur Der Installateur kommt. dort stehen. Englische Beispiele sollen auch geglosst werden und deutsche Beispiele in Bäumen brauchen keine Glossierung. In den Bäumen ist die Glossierung immer nach dem ;. Bei englischen Beispielen bitte auch glossen.
https://github.com/langsci/Syntax-der-germanischen-Sprachen Das Buch ist jetzt hier. Es wäre großartig, wenn alle Dateien in chapters übersetzt werden könnten und die deutschen Dateien dann auch einen deutschen Dateiname bekämen. Also germanic-overview.tex -> germanisch-ueberblick.tex
Mein Bekannter hat hinzugefügt:
https://github.com/langsci/Syntax-der-germanischen-Sprachen du kannst dich mit gh damit verbinden C:\Users\cabot\Downloads\germanic-passive.tex war die Datei, die Du schon hast, vielleicht hilft das
Claudia hat dann alle Dateien heruntergeladen, diese übersetzt, den Dateinamen angepasst und auch in der übergeordneten Datei, in die die Kapitel eingebunden werden, die entsprechenden Änderungen eingepflegt. Sie hat alle Änderungen wieder nach github hochgeladen.
Danach habe ich sie gebeten, die deutschen Glossierungen für die deutschen Beispiele zu entfernen. Sie hat das getan, aber danach lief LaTeX nicht mehr durch. Das lag daran, dass es in den Beispielen eckige Klammern gab und die nummerierten Beispielumgebungen \item verwenden. Nachdem ich das herausgefunden hatte und Claudia gebeten hatte, das überall anzupassen, konnte ich das Buch kompilieren. In einem weiteren Schritt wurden in den deutschen Bäumen die Glossierungen entfernt. Hierfür war es von Vorteil, dass in LaTeX Makros verwendet werden, die Inhalte beschreiben. Die Glossierung ist innerhalb eines Baumes einfach zu finden (alles nach dem Semikolon).
Ich habe dann selbst noch die Überschriften für einige Buchteile angepasst, die zentral geregelt werden, und dann hatte ich ein vorzeigbares Buch, dass ich den Studierenden zur Verfügung stellen konnte. Der Index hatte Probleme mit Groß-/Kleinschreibung, weil Sprachnamen in Adjektiven im Deutschen kleingeschrieben werden. Dazu habe ich eine github-Issue gemacht, die Claudia dann bearbeitet hat und das Ergebnis wieder hochgeladen hat. Sie hat die github-Issue selbstständig geschlossen.
Zum Editiern benutze ich den Editor Emacs. Man kann am Ende der Datei eine Anweisung geben, welche Sprache für die Rechtschreibüberprüfung verwendet werden soll. Claudia hat eigenständig, den Sprach-Code für ispell von en_US-w_accents zu de_de geändert.
Das ist der Entwurf des Buches in der aktuellen Fassung. Ich muss es noch einmal durchlesen. Bis zur ersten Rohfassung bin ich in drei bis vier Stunden gekommen. Das alles ist unglaublich.
Man kann Mitarbeiter*innen wie folgt einteilen:
- macht, was verlangt wird, aber nicht mehr
- macht, was verlangt wird und mehr und macht Dinge kaputt
- macht, mehr als verlangt wird, fragt bei riskanten Sachen nach, denkt mit und macht einfache Sachen direkt
Claude AI gehört in die letzte Klasse, ist rund um die Uhr verfügbar und billig. Im Anhang gibt es einige Anmerkungen zu Übersetzungsfehlern und die Änderungen, die ich bei der Überarbeitung des Rohentwurfs gemacht habe.
Eine Sache möchte ich noch erwähnen. Im Kapitel zur Einführung von Phrasenstrukturgrammatiken verwende ich ein Schachtelmodell. Im Englischen habe ich dafür die Bezeichnung box verwendet. Claude hat das als Kasten übersetzt. Ich verwende in meinen deutschen Texten immer Schachtel und wollte das wieder so haben. Nur in einem Kapitel kommen die Schachteln vor, und ich hätte das schnell selbst ersetzen können, aber ich wollte wissen, ob Claudia das schafft. Das Problem an dieser Ersetzung ist, dass man dazu ein gewisses Sprachverständnis oder Sprachgefühl braucht. Aus einen gefüllten Kasten muss eine gefüllte Schachtel werden. Artikel, Adjektiv und Substantiv müssen in bestimmten Merkmalen (Kasus, Genus, Numerus) übereinstimmen. Sprachwissenschaftler*innen nennen das Phänomen Kongruenz. Ich habe also eine github-Issue angelegt und Claudia gebeten, die Ersetzung vorzunehmen. Der Prompt war von mir bewusst gemein gewählt: „Bitte in der Datei germanisch-psg.tex „Kasten“ durch „Schachtel“ ersetzen.“ Till Eulenspiegel hätte genau das getan und ich hätte ihn verflucht. Claudia hat das getan, was ich mir gewünscht habe:
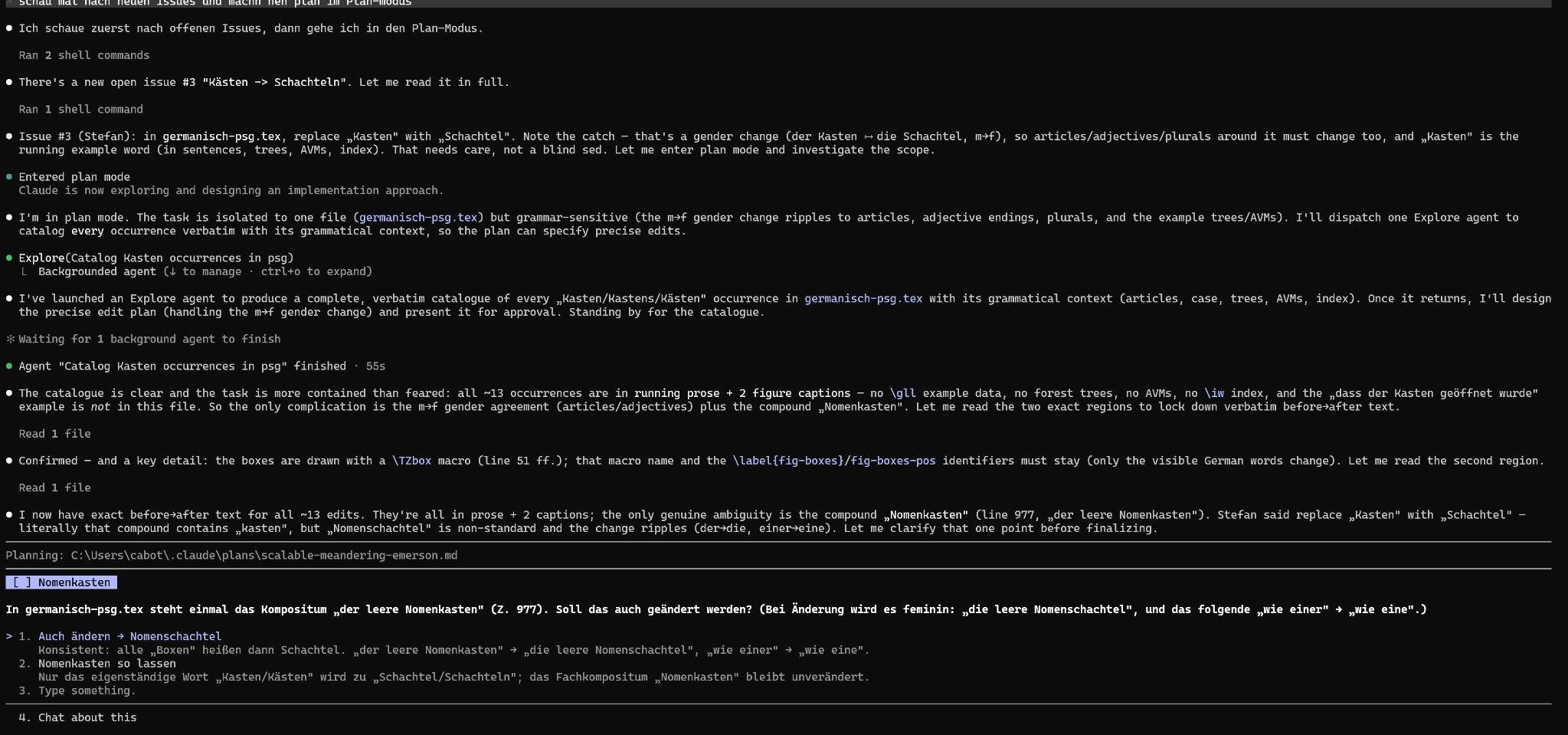
Aus irgendeinem Grund hat Claudia zu Englisch gewechselt. Is ein bisschen doof, aber ich kann ja zum Glück etwas Englisch. Erster Punkt: Sie hat das Problem in seiner ganzen Tragweite verstanden:
Issue #3 (Stefan): in germanisch-psg.tex, replace running example word (in sentences, trees, „Kasten” with „Schachtel”. Note the catch – that’s a gender change (der Kasten → die Schachtel, m→f), so articles/adjectives/plurals around it must change too, and „Kasten” is the AVMs, index). That needs care, not a blind sed. Let me enter plan mode and investigate the scope.
Sie liest den Text und stellt fest, dass nur im Haupttext das Wort Kasten bzw. Kästen vorkommt:
The catalogue is clear and the task is more contained than feared: all ~13 occurrences are in running prose + 2 figure captions – no \gll example data, and the „dass der Kasten geöffnet wurde” example is not in this file. So the only complication is the m→f gender agreement (articles/adjectives) plus the compound Nomenkasten”. Let me read the two exact regions to lock down verbatim before-after text.
Dann fragt Claudia nach, ob sie das Kompositum Nomenkasten auch in Nomenschachtel ändern soll. Nach einer entsprechenden Eingabe, erledigt sie alles fehlerfrei, puscht das Ergebnis nach github und schließt die Issue.
Ich bin platt. Diese Verständnis von grammatischen Zusammenhängen ist ein Ausbildungsziel im BA-Lehramt-Deutsch. Zu Problemen und Details siehe Anhang.
Kosten, Energieverbrauch und Schäden
Mein Bekannter hat ein Abo Claude Max 20x. Für 200$ im Monat. Claude hat im Folgendes zu den anfallenden Tokens und Kosten gesagt:
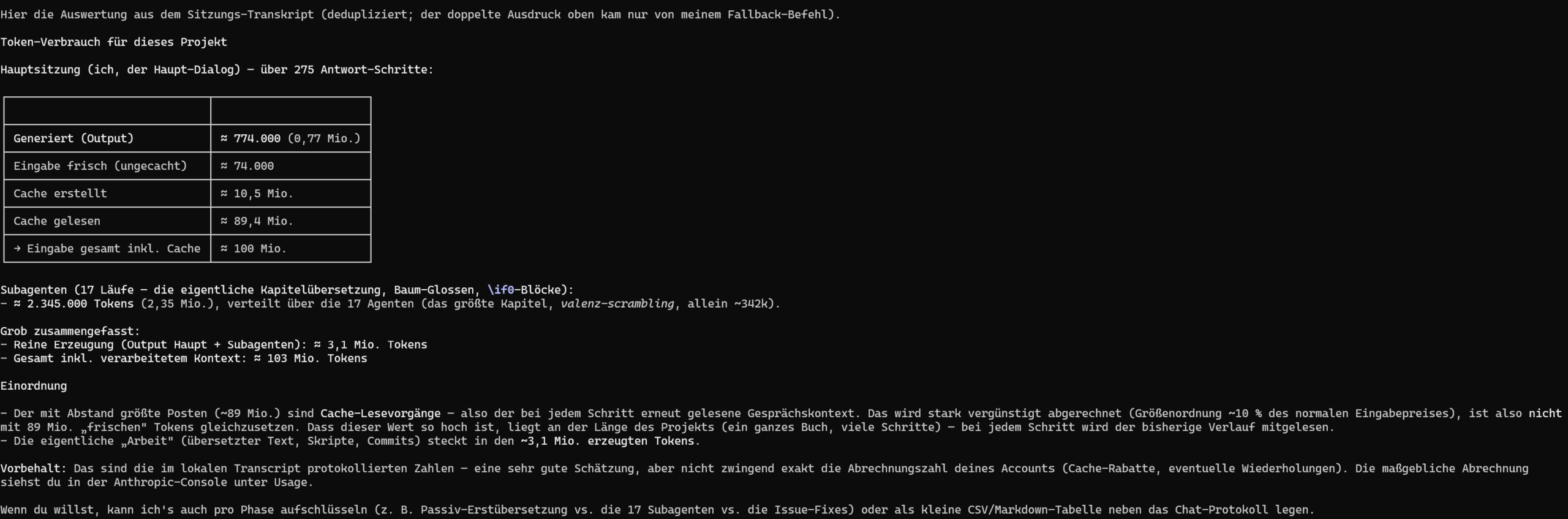
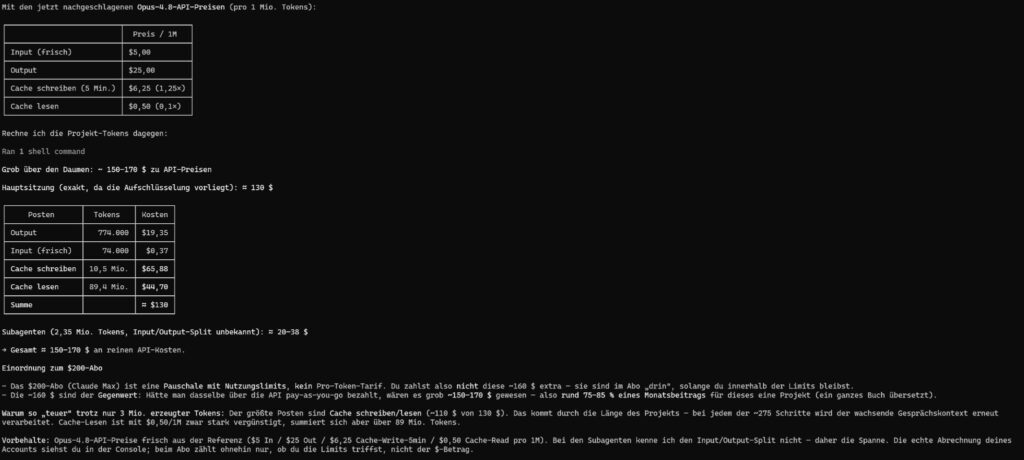
Die Kapitel wurden durch 17 Agenten parallel übersetzt. Das erklärt auch, warum es in manchen Kapitel Fehler gab, die es in anderen nicht gab, warum in manchen Leser und Leserin geschrieben wurde und in anderen einfach nur Leser. Insgesamt wurden 2,35 Millionen Token verbraucht. Dafür viele für das erneute Einlesen des Gesprächskontextes (Cache). Das entspricht in etwa 150–170$. Im Vergleich zum Aufwand, den ich gehabt hätte, sind diese Kosten gering. Es gibt jedoch andere Kosten, die hoch sind, wenn die Berechnungen stimmen. Laut der Web-Seite tokenomy.ai/ liegt der Energieverbrauch bei 30kwh und der CO₂-Ausstoß bei 7 bis 11kg, wenn kein Ökostrom verwendet wird. Leider kann man bei Anthropic nicht herausfinden, wie hoch deren Ökostromanteil ist. Ich habe zu Hause anteilig einen Jahresverbrauch von 567 kwh, habe also mit diesem Projekt ein Achtzehntel meines Jahresverbrauchs verpulvert. Beim CO₂ liegt der Ausstoß unter einem Tausendstel einer Durchschnittsdeutschen.
Sortierung und Klassifizierung von Google Scholar-Profil und Berechnung des H-Indexes
Mit Hilfe von Google Scholar-Profilen kann man sich einen ersten Eindruck über die Produktivität und den Erfolg von Wissenschaftler*innen verschaffen. Google Scholar listet alle Publikationen auf und gibt auch einen Überblick, wie oft sie zitiert wurden. Anhand der Zitationen kann man den h-Index berechnen. Wenn eine Wissenschaftler*in 20 Publikationen hat, die mindestens 20 mal zitiert wurden, ist ihr h-Faktor zwanzig. Dabei ist es unerheblich, ob sie zwei Aufsätze mit 2000 Zitationen hat. Es zählt sozusagen die Qualität in ihrer Breite und Verlässlichkeit. Der h-Faktor ist mit Vorsicht zu genießen, denn es kann kleine Spezialgebiete geben, in denen sich Personen häufig gegenseitig zitieren, so dass der h-Faktor der involvierten Personen steigt. Dennoch können die Publikationen von minderer Qualität sein. Der h-Faktor ersetzt also nicht das Lesen, aber er gibt eine erste Orientierung.
Ein Wissenschaftler hat in seinem Google Scholar-Profil Einträge, die nicht von ihm sind. Mich interessierte der h-Faktor, den er wirklich hat, d.h. nach Bereinigung des Profils.
Das war mein Prompt:
Kannst Du Dir dieses Google Scholar-Profil angucken und mir daraus eine Exel-Tabelle machen, in der alle Linguistik-Zitatioen in einer Spalte und alle anderen in einer anderen Spalte enthalten sind und dann jeweils die Summe der Spalten berechnen und den h-Faktor für die Linguistik-Publikationen? https://scholar.google.de/citations?user=XY
Claude AI konnte wegen Einstellungen auf der Google-Seite nicht auf das Profil zugreifen und hat mich gebeten, eine Excel-Tabelle zu exportieren. Die Möglichkeit scheint es nicht mehr zu geben. Claude meinte aber, ich könne auch einfach mit Copy&Past die Seite reinpasten, das sei kein Problem, weil er auch mit unstrukturiertem Text klarkomme. Das, was man mit Copy & Paste bekommt ist wirklich wild, aber Claude konnte damit was anfangen. Es konnte die zitierten Aufsätze den Fachgebieten Linguistik bzw. einem wilden Mix aus anderen Gebieten zuordnen, hat eine ordentliche Tabelle sortiert nach Zitationshäufigkeit für beide Gruppen erzeugt und auch noch angegeben, wodurch diese Mischung der Fachgebiete wahrscheinlich entstanden ist. Der h-Faktor für Linguistik wurde korrekt berechnet.
Schlussfolgerungen
Das Buch selbst zu übersetzen hätte mich ein halbes oder ein ganzes Jahr gekostet, so war es mit wenigen Stunden Arbeit erledigt. Ich muss es noch einmal kontrolllesen, das wird mehrere Wochen dauern, aber dann ist es fertig. Ohne KI hätte ich es wohl nie ins Deutsche übertragen.
Das Sortieren des Google Scholar Profils hätte meine Sekretärin machen können. Dazu hätte ich ihr aber genau erklären müssen, was sie tun soll, was mich Zeit gekostet hätte und sie hätte dafür wirklich lange gebraucht. Dass Claudia aus diesen Daten den h-Faktor bestimmen kann, ist auch erstaunlich.
Die Konsequenz ist, dass in Zukunft Arbeitsplätze für Sekretariatsaufgaben wegfallen werden. Textbearbeitungsaufgaben, die früher studentische Hilfskräfte erledigt haben, werden wegfallen. Einfache bis mittelschwere Programmieraufgaben werden automatisch 24 h an 7 Tagen in der Woche erledigt. Man braucht also auch keine mittelmäßigen Programmierer*innen mehr. Man braucht nur noch top-ausgebildete Menschen, die konzeptuell denken können. Das ist bitter für viele von uns, aber es ist die Wahrheit.
Quellen
Bergt, Svenja. 2026. Umweltfolgen von künstlicher Intelligenz: 250 Eiffeltürme Elektronikschrott. taz. Berlin. (https://taz.de/Umweltfolgen-von-kuenstlicher-Intelligenz/!6183982)
State of Brand. 2026. 80% of Companies Cut Jobs for AI. It Didn’t Improve Their Returns. Not Even a Little. (https://www.thestateofbrand.com/news/ai-job-cuts-not-improving-returns)
Anhang: Änderungen am automatisch übersetzten Text
Linguists wurde im ersten Kapitel nach Linguistinnen und Linguisten übersetzt und ich habe es in Linguist*innen geändert. Das wäre sicher auch automatisch gegangen, aber ich wollte das selbst korrigieren. Claude AI hat aber nicht konsistent beide Formen verwendet. In späteren Kapiteln stand einfach Hörer und in einem Kapitel wurde sogar das generische Femininum Hörerin verwendet. Das liegt daran, dass die Aufgabe von Claude AI in Teilaufgaben geteilt wurde und von 17 autonomen Agenten bearbeitet wurde. Diese haben unterschiedliche Fehler gemacht. Zum Beispiel wurde in einem Kapitel nach dem Doppelpunkt klein begonnen, auch wenn ganze Sätze folgten. In einem anderen Kapitel wurde mitten in Komposita ein Bindestrich gemacht und klein weitergeschrieben.
Beim kritischen Lesen der Übersetzung sind mir Dinge aufgefallen, die auch im englischen Buch schon falsch waren. Die habe ich dann auch korrigiert.
Die PDF-Datei mit der ursprünglichen Übersetzung und meinen Anmerkungen befindet sich auf github.
Hier sind die Änderungen, die ich nach der Übersetzung gemacht habe, auf github:
- Vorwort
- Danksagung
- Kapitel 1: Überblick
- Kapitel 2: Phänomene
- Kapitel 3: Phrasenstrukturgrammatiken und X-Theorie
- Kapitel 4: Valenz, Argumentabfolge und Adjunktstellung
- Kapitel 5: Der Verbalkomplex
- Kapitel 6: Verbstellung: Verberst- und Verbzweitstellung
- Kapitel 7: Passiv
- Kapitel 8: Satztypen und Expletivpronomina
- Kapitel 9: Ausblick
- Anhang: Lösungen
Der krasseste Fehler war die Übersetzung des Satzes: „Section6.1.4 is dedicated to fronting in English and verb-second clauses in German (and the other Germanic languages).“ nach „Abschnitt 6.1.4 ist dem Vorfeld-Voranstellen im Englischen und den Verbzweitsätzen
im Deutschen (und den anderen germanischen Sprachen) gewidmet.“ Es gibt im Englischen kein Vorfeld. Dieser Begriff wird für das Englische nicht benutzt. Das hat sich Claude einfach aus den Fingern gesogen. Richtig wäre gewesen: „Abschnitt 6.1.4 ist der Voranstellung im Englischen und den Verbzweitsätzen im Deutschen (und den anderen germanischen Sprachen) gewidmet.“
Dinge, die mir aufgefallen sind: Claude AI hat viel Präteritum verwendet. Ich verwende das fast nie und habe die entsprechenden Stellen zum Perfekt korrigiert (hat gezeigt, statt zeigte).
Das Wort dies verwende ich ebenfalls nicht. Ich habe es durch das bzw. dieses ersetzt.
Mitunter werden Pronomina falsch verwendet. Das liegt daran, dass das Englische ein anderes Genussystem hat, so dass der Pronomenbezug mitunter nicht klar ist. Claude AI versteht den Text nicht und nimmt dann einfach das. Auch der Bezug auf zitierte Personen funktioniert nicht immer. Es wird meist das maskuline Pronomen verwendet. So für Jane Grimshaw und Pauline Jacobson. Um das richtig aufzulösen, wäre ein Blick in die BibTeX-Datenbank nötig.
Manche Sätze sind zu komplex und dann unverständlich.
Claudia hat nach Kommandos wie \spr geschweifte Klammern hinzugefügt. Das ist im Prinzip richtig, weil LaTeX sonst das folgende Leerzeichen verschlucken würde, aber ich habe das Makro mit \xspace definiert, so dass das ausgeglichen wird. Die geschweiften Klammern schaden aber auch nicht.
Einmal bezog sich der Text auf die englische Übersetzung eines deutschen Beispiels, das aber gelöscht wurde.
Eine Vergangenheitsform pointed wurde im Plural übersetzt, weil zwei Werke zitiert wurden, da es sich aber um denselben Autor handelte, ist Singular angebracht.
Bei der Übersetzung des Satzes „The PP über dieses Thema depends on Vortrag ‘talk’, which is part of the VP headed by zu halten ‘to hold’, which is in turn embedded under gebeten `asked’.“ kam der folgende unverständliche Satz heraus: „Die PP über dieses Thema hängt von Vortrag ab, das Teil der VP ist, deren Kopf zu halten ist, das wiederum unter gebeten eingebettet ist.“ Ich habe das wie folgt geändert: „Die PP über dieses Thema hängt vom Nomen Vortrag ab, das Teil der VP ist, deren Kopf zu halten ist, und die unter gebeten eingebettet ist.“
Als Fehler muss man verbletzte Sätze einordnen. Richtig wäre Verbletztsätze gewesen.
Zusammenfassend kann man sagen, dass die Übersetzung gut war. Als Leser*in kann man bereits mit der uneditierten Übersetzung sehr gut arbeiten.